In a previous post, I talked about the voice of the customer (VoC), voice of the process (VoP) and the necessity of combining the two when specifying a product. Here, I’d like to offer a general method for applying this in the real world, which can be implemented as a template in Excel.
Recap
I showed that there was a cost function associated with any specification that derived from both the VoC (expressed as tolerances or specification limits) and from the process capability. An example cost function for a two-sided tolerance is reproduced below.

Percent of target production costs given an average production weight and four different process capabilities.
I argued that, given this cost function, specifying a product requires specifying both the product specification limits (or tolerances) and the minimally acceptable process capability, Cpk. Ideally, both of these should flow down from a customer needs analysis to the finished product, and from the finished product to the components, and so on to materials.
Requirements flow down and up
To flow all requirements down like this, we would need to know the transfer functions, 
As an illustration, we will use the design of a battery (somewhat simplified), where we have to meet a minimum requirement that is the sum of component parts. The illustration below shows the component parts of a battery, or cell. It includes a container (or “cell wall”), positive and negative electrodes (or positive and negative “plates”), electrolyte and terminals that provide electrical connection to the outside world. Usually, we prefer lighter batteries to heavier ones, but for this example, we’ll suppose that a customer requires a minimum weight. This requirement naturally places limits on the weight of all components.
In the absence of transfer functions, we often make our best guess, build a few prototypes, and then adjust the design. This may take several iterations. A better approach is to estimate the weight specification limits and minimum Cpk by calculation before any cells are actually built.
![General drawing of the structure of aircraft battery's vented type NiCd cell. Ransu. Wikipedia, [http://en.wikipedia.org/wiki/ File:Aircraft_battery_cell.gif]. Accessed 2014-04-04.](https://tomhopper.me/wp-content/uploads/2014/05/aircraft_battery_cell.gif)
General drawing of the structure of aircraft battery’s vented type NiCd cell. Ransu. Wikipedia, [http://en.wikipedia.org/wiki/ File:Aircraft_battery_cell.gif]. Accessed 2014-04-04.
Suppose the customer specifies a cell minimum weight of 100 kg. From similar designs, we know the components that contribute to the cell mass and have an idea of the percentage of total weight that each component contributes.
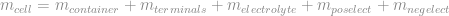
Each individual component is therefore a fraction fm of the total cell mass, e.g.

More generally, for a measurable characteristic c, component i has an expected mean or target value of 

In our example, we may know from similar products or from design considerations that we want to target the following percents for each fraction fm:
- 5% for container
- 19% for terminals
- 24% for electrolyte
- 26% for positive electrodes
- 26% for negative electrodes
Specification Limits
- Upper Specification Limit (USL)
- The maximum allowed value of the characteristic. Also referred to as the upper tolerance.
- Lower Specification Limit (LSL)
- The minimum allowed value of the characteristic. Also referred to as the lower tolerance.
Since the customer will always want to pay as little as possible, a specified lower weight of 100 kg is equivalent to saying that they are only willing to pay for 100 kg of material; any extra material is added cost that reduces our profit margin. If we tried to charge them for 150 kg of material, they would go buy from our competitors. The lower specification limit, or lower tolerance, of the cell weight is then 100 kg.
If the customer does not specify a maximum weight, or upper specification limit, then we determine the upper limit by the maximum extra material cost that we are willing to bear. In this example, we decide that we are willing to absorb up to 5% additional cost per part. Assuming that material and construction contributes 50% to the total cell cost, the USL is then 110 kg. To allow for some variation, we can set a target weight in the middle: 105 kg. From data on previous designs and the design goals, we can apportion the target weight to each component of the design, as shown in the table below.
We can apply the same fractions to the cell USL and LSL to obtain a USL and LSL of each component. As long as parts are built within these limits, the cell will be within specification. The resulting specification for cell and major subcomponents is illustrated in table [tblSpecification]. Further refinement of the allocation of USL and LSL to the components is possible and may be needed if the limits do not make sense from a production or cost perspective.
| Cell | 100% | 105 | 100 | 110 |
| Container | 5% | 5.2 | 5 | 5.5 |
| Terminals | 19% | 19.9 | 19 | 20.9 |
| Electrolyte | 24% | 25.2 | 24 | 26.4 |
| Positive electrodes | 26% | 27.3 | 26 | 28.6 |
| Negative electrodes | 26% | 27.3 | 26 | 28.6 |
Variance of components and Cpk
When a characteristic is due to the sum of the part’s components, as with cell mass, the part-to-part variation in the characteristic is likewise due to the variation in the components. However, where the characteristic adds as the sum of the components,
the variance, 
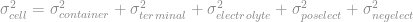
The variance of any individual component is therefore a function of the total parent part variance

or

Since this is true for all components, the two fractions 
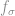

More generally, for measurable characteristic 


Since the given 

Calculating Specification Limits
In general, there are two conflicting goals in setting specifications:
- Make them as wide as possible to allow for manufacturing variation while still meeting the VoC.
- Make them as narrow as possible to stay near the minimum of the cost function.
For this, Crystall Ball or iGrafx are very useful tools during development, as we can simulate a set of arts or processes, analyze the allowed variation in the product and easily flow that variation down to each component. In the absence of these tools, Minitab or Excel can be used to derive slightly less robust solutions.
Calculating from Customer Requirements
- Identify any customer requirements and set specification limits (USL and LSL) accordingly. If the customer requirements are one-sided, determine the maximum additional cost we are willing to accept, and set the other specification limit accordingly. Some approximation of costs may be needed.
- If no target is given, set the target specification for each requirement as the average of USL and LSL.
- Set the minimum acceptable Cpk for each specification. Cpk = 1.67 is a good starting value. Use customer requirements for Cpk, where appropriate, and consider, also, whether the application requires a higher Cpk (weakest link in the chain….
- Calculate the maximum allowed standard deviation to meet the Cpk requirement as
.
- For each subcomponent (e.g. the cell has subcomponents of container, electrodes, electrolyte, and so on), apportion the target specification to each of the subcomponents based on engineering considerations and judgement. If the fractions
are known,
.
- Calculate the fraction
(or percent) of the parent total for each subcomponent if not already established in step (5).
- Calculate the USL and LSL for each subcomponent by multiplying the parent USL and LSL by the component’s fraction of parent (from step 6).
and
.
- Estimate the allowed standard deviation
for each subcomponent as
- Calculate the minimum allowed Cpk for each subcomponent from the results of (5), (7) and (8), using the target,
, for the mean,
.
- Repeat steps (5) through (9) until all components have been specified.
- For each component, report the specified USL, LSL, target T and maximum Cpk.


Calculating from Process Data
When there is no clear customer-driven requirement or clear requirement from parent parts (e.g. dimensional specifications that can be driven by the fit of parts), but specification limits are still reasonably needed, we can start from existing process data.
This is undesirable because any change to the process can force a change to the product specification, without any clear understanding of the impact on customer needs or requirements; the VoC is lost.
The calculation of USL and LSL from process data is also somewhat more complicated, as we have to use the population mean and standard deviation to determine where to set the USL and LSL, without really knowing what that mean and standard deviation are.
In the real world, we have to live with such constraints. To deal with these limitations, we will use as much data as is available and calculate the confidence intervals on both the mean and the standard deviation. The calculation for USL and LSL becomes


where 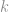
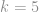
We always use the upper 95% confidence interval on the standard deviation. We don’t care about the lower confidence interval, since a small
- Calculate the mean (
) from recent production data. In Excel, use the AVERAGE() function on the data range.
- Calculate the standard deviation (
) from recent production data. In Excel, you can use the STDEV() function on the data range.
- If the order of production data is known, or SPC is in use, a better method is to use the range-based estimate from the control charts. This will be discussed in subsequent training on control charts.
- Count the number of data points, n, that were used for the calculations (1) and (2). You can use the COUNT() function on the data range.
- Calculate the 95% confidence level on the mean. In Excel, this is accomplished with
In Excel 2010 and later, TINV() should be replaced with T.INV.2T().
- Calculate the 95% confidence interval on the mean as
and
.
- Calculate the upper and lower 95% confidence limits on the standard deviation. In Excel, this is accomplished with
and
In Excel 2010 and later, CHIINV() can be replaced with CHISQ.INV.RT() for improved accuracy.
- Calculate the LSL as
. You might use a value other than 5 if the customer requirements or application require a higher process Sigma.
- Calculate the USL as
.
- For each subcomponent (e.g. the cell has subcomponents of positive electrode, negative electrode, electrolyte, and so on), apportion the parent part mean to each of the subcomponents based on engineering considerations and judgement. If the fractions
.
- If the the fraction (or percent)
- Calculate the USL and LSL for each subcomponent by multiplying the parent USL and LSL by the component’s fraction of parent (from step 6).
- Estimate the allowed standard deviation
- Calculate the minimum allowed Cpk for each subcomponent from the results of (5), (7) and (8), using the target
for the mean,
.
- Repeat steps (9) through (13) until all components have been specified.
- For each component, report the specified USL, LSL, target T and maximum Cpk.

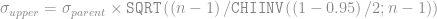




You must be logged in to post a comment.