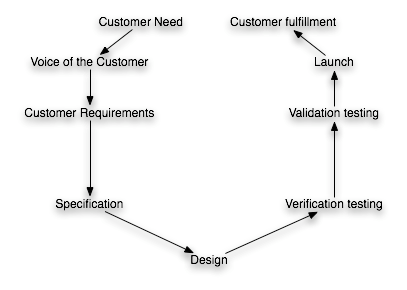
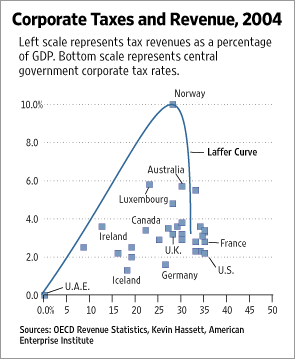
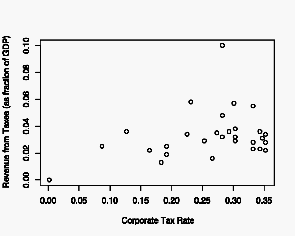
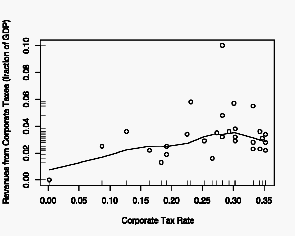
I’ve worked in and managed a few R&D and test labs in my career. Lately, I’ve been thinking about success factors for those labs. At a high level, I believe that a successful Lab has four key attributes: good data; the right data; the ability to communicate the data clearly and effectively; and a relentless pursuit of perfection.
Good Data
Good data is accurate, has a known precision, and is reproducible by your lab and by third parties. This requires good calibration practices, careful evaluation of measurement uncertainty and documented test methods. In short, you need:
- good calibration procedures and a calibration schedule that keeps equipment in calibration;
- good procedures for measuring and documenting the measurement uncertainty and sources of error;
- good procedures for how to set up tests, collect data and then utilize the information from calibration and measurement system analysis in your data analysis.
Yes, this all boils down to standard work. I’ve said it before, and I’ll say it again. Despite the common opinion that standard work is an impediment creative R&D-type work, I’ve found just the opposite is true.
This is harder to accomplish than it sounds, but there’s plenty of resources available to help. There’s even an international standard that a lab can be accredited against: ISO 17025.
The Right Data
Ensuring that you’re collecting the right data makes collecting good data look easy. Getting the right data means performing a test that provides useful information. There are two components to this: testing the expected conditions; and testing the boundary conditions.
If you’re doing your own testing, then testing the expected conditions is easy. You know what you’re thinking and what you expect, and you go test it. If I want to test if ice freezes at zero degrees Celsius, then I test it. However, if the testing is outsourced, then things get complicated. Suppose I live in Denver, Colorado, and I want to test if ice freezes at zero degrees Celsius in the winter. To test it myself, I might stick a thermometer in a glass of water, put it outside and wait. Suppose, though, that the testing is outsourced to a lab in a place like Bangladesh, India, that’s hotter, lower in altitude and more humid. They can provide an answer, but will they address my intent? As the test requester, I may not ask the right question; as the test group, they may leap to test without fully understanding why I’m asking. This sort of confusion actually happens quite frequently, even when the test group and the requester are in the same building. It can be months before people realize that their question was only partially answered.
Paradoxically, testing the boundary conditions is difficult when you’re doing your own testing, while the communication errors described above make it easier for an outside lab to test the boundary conditions. It’s almost inevitable that they’ll test some boundary conditions. The reason for this is that boundary conditions are defined by one’s assumptions, and people are generally pretty poor at identifying and thinking through their own assumptions. Mentally, we tear right through the assumptions to the interesting bits. The outside lab, though, isn’t going to be quite testing the expected conditions; they’ll always be nearer at least one set of boundary conditions.
One common solution used by labs is to develop a detailed questionnaire to try to force their customers to detail their request in the lab’s terms. I’ve done this myself. It doesn’t work. A questionnaire, like a checklist, can help capture the things you know you’d otherwise overlook, but neither a questionnaire nor a checklist can bridge a communication gap.
The solution that works is to send the lab personnel out into the gemba; to go and see the customer’s world and understand what they’re doing and why they’re making their request. This is difficult. The lab may be geographically distant from the gemba. People working in a lab often got there by being independent thinkers and workers, and not by being very gregarious. Labs are also paid or evaluated for the testing they do; not for the customer visits they make. A lab manager needs to be able to overcome these obstacles.
Communication
Once the lab has the right, good data, there’s still one big challenge left. All that data goes to waste if it isn’t communicated effectively. This means understanding that the data tells a story, knowing what that story is, and then telling that story honestly and with clarity. One could write several books on this subject. I direct your attention to the exceptional works of Edward Tufte, especially The Visual Display of Quantitative Information, an excellent NASA report by S. Katzoff titled Clarity in Technical Reporting, and the deep works of William S. Cleveland, including The Elements of Graphing Data and Visualizing Data. If you don’t have these in your library, then you’re probably not communicating as clearly and effectively as you should.
Effective communication is critical even when you’re doing your own testing. It provides a record of your work so that others can follow in your footsteps. Without effective communication, whatever you learn stays with you, and you lose the ability to leverage the ideas and experience of others.
Pursuing Perfection
While we have to get the job done today, we probably haven’t delivered everything your customer needed. There’s always opportunity for improvement. A good lab recognizes this, constantly engages in self reflection and finds ways to improve. This is a people-based activity. A good manager enables this critical self-reflection and supports and encourages the needed changes.
Such critical self-reflection is not always easy. In many business environments, an admission of imperfection is an invitation to be attacked, demoted, or fired. Encouraging the self-reflection that is crucial to improvement requires building trust with your employees; providing a safe environment. Employees have to be comfortable talking about their professional faults, having others talk about those faults, and they have to believe that they can improve.
Being genuine and honest can help a manager move their group in this direction. Ensuring that there are no negative consequences to the pursuit of perfection will also help. Unfortunately, it’s not entirely up to the manager; it’s a question of politics, policies and corporate culture. Effective managers and leaders need to navigate these waters for the good of their team. They’ll do this better with the support and involvement of their team.