In my previous post, I gave a brief introduction to populations and samples, and stated that sample size impacts our ability to know what a population really looks like. In this post, I want to show this relationship in more detail. In future posts, I will look at how sample size considerations impact our engineering process and what impacts this has on the business.
Mean and sample size
The error in our estimate of the mean, 


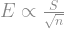
We can visualize this easily enough by plotting the 95% confidence interval. When we sample and calculate the sample mean (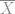
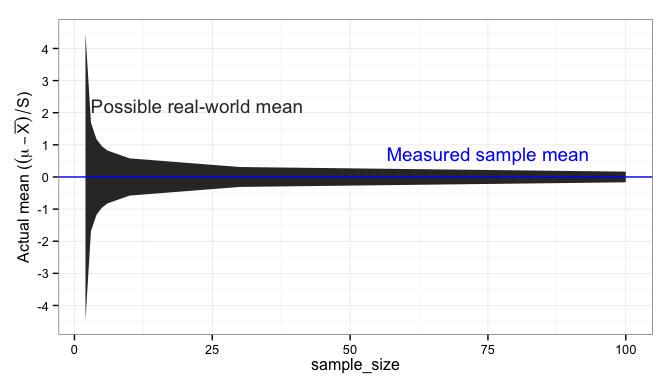
This graph shows the 95% confidence region for the true population mean,
Standard deviation and sample size
Likewise, when we calculate the sample standard deviation, 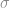
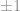
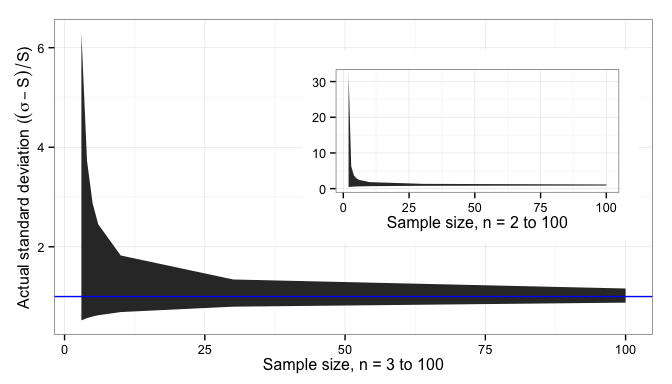
Proportion and sample size
For proportions, the situation is similar: there is a 95% chance that the true sample proportion, 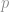
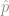
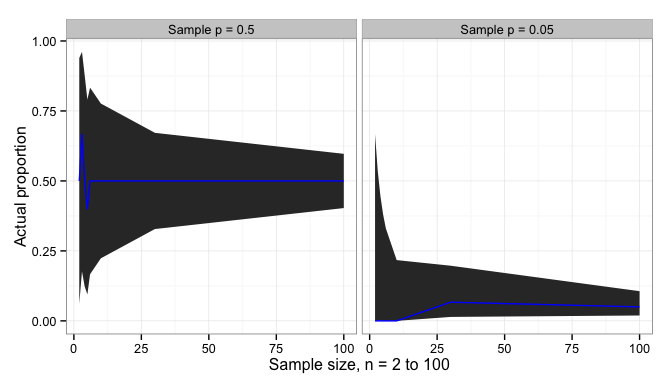
For small
Process capability and production costs
The cost of poor quality in product or process design can be characterized by the Cpk:
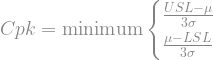
Where USL is the upper specification limit (also called the upper tolerance) and LSL is the lower specification limit (or lower tolerance).
We can estimate the defect rate (defects per opportunity, or DPO) from the Cpk:

That probability function is calculated in R with pnorm(3 * Cpk - 1.5) and in Excel with NORMSDIST(3 * Cpk - 1.5). The 1.5 is a typical value used to account for uncorrected or undetected process drift.
Since we don’t know
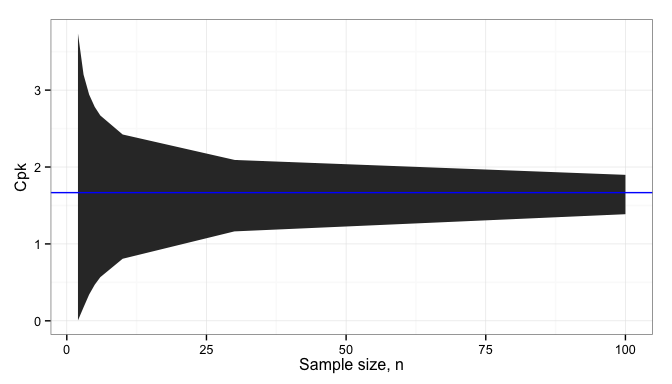
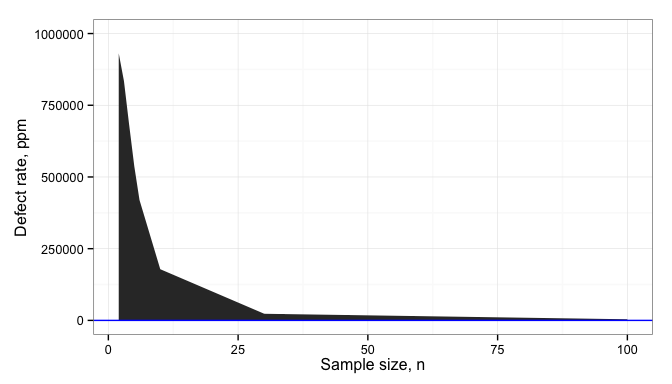
Below the blue line, our product or process is failing to meet customer expectations, and will result in lost customers or higher warranty costs. Above the blue line, we’ve added more cost to the production of the product than we need to, reducing our gross profit margin. Since that gray band doesn’t completely disappear, even at 100 samples, we can never eliminate these risks; we have to find a way to manage them effectively.
The impact of this may be more evident when we convert from Cpk to defect rates (ppm):
Summary and a look forward
With a fair sampling process, samples will look similar to—and statistically indistinguishable from—the population that they were drawn from. How much they look like the population depends critically on how many samples are tested. The uncertainties, or errors in our estimates, resulting from sample size decisions have impacts all through our design analysis and production planning.
In the next post, I will explore in more detail how these uncertainties impact our experiment designs.

2 thoughts on “Sample Size Matters: Uncertainty in Measurement”