Part of my day job involves monitoring the renewable energy market, and particularly keeping abreast of storage technologies. It’s like combining my hobby with my job.
A new wind turbine design was recently announced, the SeaTwirl. It’s an off-shore turbine design using vertical blades. The key technological advance here is that it includes a method to store energy, so that it can continue to produce electricity when the wind stops blowing. This ability to deliver a constant output is important, because, as you may have heard, wind energy is intermittent; you only get electricity when the wind blows, and only to the degree that it’s blowing. Demand, unfortunately, doesn’t follow wind’s intermittancy—nobody stops to check that the wind is blowing before they turn on their lights—and the utilities, transmission system operators and distribution system operators all have to supply electricity to meet demand.
The SeaTwirl stores energy by integrating an unusual wind turbine design with a pumped hydro system. It has the turbine blades on a large circular ring, which rotates parallel to the water’s surface kind of like a hula-hoop. This ring is hollow (more or less), and is filled up with water when the wind blows. When the wind stops blowing, the momentum of the water keeps the tube spinning, generating electricity, and the water is allowed to drain back out, spinning a hydro turbine to generate electricity.
The nice thing about this is that the storage can always be “recharged” and it’s “free.” Or at least it seems to be. If you’ve ever held a bucket while spinning around, you know that spinning with an empty bucket takes a lot less effort than spinning around with a full bucket. In part, this is because of a property known as the moment of inertia. The heavier or larger a spinning object gets, the more it resists changes to its rate of rotation (or rpm).
If the SeaTwirl is filling up this horizontal “hula-hoop” with water, then the weight of the tube is increasing and so is the moment of inertia. As the moment of inertia increases, the energy needed to reach a given rpm increases. Wind turbines normally generate electricity in proportion to the wind speed, because the rpm of the blades is proportional to the wind speed. Increase the moment of inertia and you decrease the rpm, which means you generate less electricity for a given wind speed.
Now comes the physics. For something shaped like a hula-hoop, the moment of inertia, I, is calculated from the mass, M, and the radius of the hoop, R, according to:
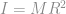
The energy, E, in a spinning object is equal to the moment of inertia times the speed of rotation, ω, according to

If we know the energy (because we know the wind speed), then we can calculate the speed of rotation, ω, by rearranging that equation to get ω on the left-hand side:
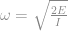
We can then replace I with mass and radius from the first equation to get

So we can see that, if we don’t change the energy E (or don’t change the wind speed), and don’t change the radius R of the spinning hoop, then increasing the mass M results in a slower rate of rotation.
From SeaTwirl’s website and press releases, we can estimate how big the SeaTwirl is, which will let us estimate how much slower a full SeaTwirl will spin than an empty one, and therefore how much less electricity must be generated. We can calculate this by taking the ratio of ω full to ω empty, so that the parts that we don’t have to know E and R.

For the SeaTwirl, we now have to find out what R is, and estimate M for both filled and empty
The whole turbine assembly is made of composite materials, which probably have a density,  , of around 2500 kilograms per cubic meter (similar to fiberglass). Water has a density,
, of around 2500 kilograms per cubic meter (similar to fiberglass). Water has a density,  , of near 1000 kilograms per cubit meter (depending on temperature). The diameter of the turbine will be near 180 meters, so the radius, R, of our “hula-hoop” is half that, or 90 meters. From the pictures, it looks like the thickness of that hula-hoop is a few percent of the total diameter of the turbine, so we can figure an outside diameter of the “hula-hoop” of about 2 meters, for a radius, r, of 1 meter. Figure that at least ten percent of this is composite, and the rest is the hollow, water-filled portion.
, of near 1000 kilograms per cubit meter (depending on temperature). The diameter of the turbine will be near 180 meters, so the radius, R, of our “hula-hoop” is half that, or 90 meters. From the pictures, it looks like the thickness of that hula-hoop is a few percent of the total diameter of the turbine, so we can figure an outside diameter of the “hula-hoop” of about 2 meters, for a radius, r, of 1 meter. Figure that at least ten percent of this is composite, and the rest is the hollow, water-filled portion.
To estimate the weight of the water in the “hula-hoop,” we can approximate the water as being a cylinder of radius  and length equal to the circumference of the “hula-hoop,”
and length equal to the circumference of the “hula-hoop,”  . The volume of such a cylinder is equal to the cross-sectional area of the water column,
. The volume of such a cylinder is equal to the cross-sectional area of the water column,  times the length of the column, l. The total mass of the water,
times the length of the column, l. The total mass of the water,  is the density times this volume.
is the density times this volume.

Plugging in our estimates for the above values gives us
 kg
kg
That’s a lot of water.
Now for the empty “hula-hoop.” We can treat it in the same way: a cylinder of material of radius r, length . However, we don’t want to calculate for a solid cylinder of composite; we have to subtract out the hollow part with radius  . So the mass of the composite is
. So the mass of the composite is

 kg
kg
So the water more than doubles the weight of the hoop.
From the picture, you can see that there’s another hoop at the top, and the two hoops are connected by the turbines, which combined are probably worth at least another hoop in weight, so we can further assume that the mass of this bottom hoop, empty, is roughly one-third of the total mass of the movable parts of turbine.
The mass of the turbine, empty, is therefore about 1200000 kg, or 1200 tons. Filled with water, this goes up to about 1900000 kg, or 1900 tons. Empty, that’s maybe twice the largest off-shore turbine currently in existence, but this thing is easily twice as big as any current turbine, so our estimate appears to be in the right neighborhood.
Now we go back to our equation for the ratio of the rotational velocities, ω, and plug in these weights:

So we get about 80% as much electricity from a water-filled turbine as from an empty one, when the wind blows. This is a direct efficiency loss due to the storage of energy in the spinning-water-hoop.
In addition, there’s the efficiency losses in loading water into the hoop, or “charging” the hoop, and the efficiency losses of “discharging” the hoop, running the water back out through a hydro turbine. Pumped hydro is usually about 72% efficient, or less, in each direction, so the total round-trip efficiency of storage + discharge is about 50% efficient. There are a lot of other storage technologies that do at least this good, if not better.
These two figures, the 80% efficiency loss of just operating the turbine and the 50% storage-discharge efficiency, can be used to directly compare SeaTwist with other wind turbine + storage technology solutions. Any storage technology that has at least a 50% round-trip efficiency and increases the total system cost by less than 20% over the system’s operating lifetime will outperform SeaTwist in terms of return on investment.









You must be logged in to post a comment.