When analyzing data, I have often found it useful to think of the data as being one of four main types, according to the typology proposed by Stevens.[1] Different types of data have certain characteristics; understanding what type of data you have helps with selecting the analysis to perform perform while preventing basic mistakes.
The types, or “scales of measurement,” are:
- Nominal
- Data identifying unique classifications or objects where the order of values is not meaningful. Examples include zip codes, gender, nationality, sports teams and multiple choice answers on a test.
- Ordinal
- Data where the order is important but the difference or distance between items is not important or not measured. Examples include team rankings in sport (team A is better than team B, but how much better is open to debate), scales such as health (e.g. “healthy” to “sick”), ranges of opinion (e.g. “strongly agree” to “strongly disagree” or “on a scale of 1 to 10”) and Intelligence Quotient.
- Interval
- Numeric data identified by values where the degree of difference between items is significant and meaningful, but their ratio is not. Common examples are dates—we can say 2000 CE is 1000CE + 1000 years, but 1000 CE is not half of 2000 CE in any meaningful way—and temperatures on the Celsius and Fahrenheit scales, where a difference of 10° is meaningful, but 10° is not twice as hot as 5°.
- Ratio
- Numeric data where the ratio between numbers is meaningful. Usually, such scales have a meaningful “0.” Examples include length, mass, velocity, acceleration, voltage, power, duration, energy and Kelvin-scale temperature.
The generally-appropriate statistics and mathematical operations for each type are summarized in table 1.
While this is a useful typology for most use, and certainly for initial consideration, there are valid criticisms of Stevens’ typology. For example, percentages and count data have some characteristics of ratio-scale data, but with additional constraints. e.g. the average of the counts 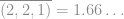
Types of data in R
R[2] recognizes at least fifteen different types of data. Several of these are related to identifying functions and other objects—most users don’t need to worry about most of them. The main types that industrial engineers and scientists will need to use are:
- numeric
- Real numbers. Also known as double, real and single (note that R stores all real numbers in double-precision). May be used for all scales of measurement, but is particularly suited to ratio scale measurements.
- complex
- Imaginary real numbers can be manipulated directly as a data type using
x <- 1 + i2
or
x <- complex(real=1, imaginary=2)
Like type numeric, may be used for all scales of measurement.
- integer
- Stores integers only, without any decimal point. Can be used mainly for ordinal or interval data, but may be used as ratio data—such as counts—with some caution.
- logical
- Stores Boolean values of TRUE or FALSE, typically used as nominal data.
- character
- Stores text strings and can be used as nominal or ordinal data.
Types of variables in R
The above types of data can be stored in several types, or structures, of variables. The equivalent to a variable in Excel would be rows, columns or tables of data. The main ones that we will use are:
- vector
- Contains one or many elements, and behaves like a column or row of data. Vectors can contain any of the above types of data but each vector is stored, or encoded, as a single type. The vector
c(1, 2, 1, 3, 4) ## [1] 1 2 1 3 4
is, by default, a numeric vector of type double, but
c(1, 2, 1, 3, 4, "name") ## [1] "1" "2" "1" "3" "4" "name"
will be a character vector, or a vector where all data is stored as type character, and the numbers will be stored as characters rather than numbers. It will not be possible to perform mathematical operations on these numbers-stored-as-characters without first converting them to type numeric.
- factor
- A special type of character vector, where the text strings signify factor levels and are encoded internally as integer counts of the occurrence of each factor. Factors can be treated as nominal data when the order does not matter, or as ordinal data when the order does matter.
- array
- A generalization of vectors from one dimension to two or more dimensions. Array dimensions must be pre-defined and can have any number of dimensions. Like vectors, all elements of an array must be of the same data type. (Note that the letters object used in the example below is a variable supplied by R that contains the letters a through z.)
# letters a - c in 2x4 array array(data=letters[1:3], dim=c(2,4)) ## [,1] [,2] [,3] [,4] ## [1,] "a" "c" "b" "a" ## [2,] "b" "a" "c" "b" # numbers 1 - 3 in 2x4 array array(data=1:3, dim=c(2,4)) ## [,1] [,2] [,3] [,4] ## [1,] 1 3 2 1 ## [2,] 2 1 3 2
- matrix
- A special type of array with the properties of a mathematical matrix. It may only be two-dimensional, having rows and columns, where all columns must have the same type of data and every column must have the same number of rows. R provides several functions specific to manipulating matrices, such as taking the transpose, performing matrix multiplication and calculation eigenvectors and eigenvalues.
matrix(data = rep(1:3, times=2), nrow=2, ncol=3) ## [,1] [,2] [,3] ## [1,] 1 3 2 ## [2,] 2 1 3
- list
- Vectors whose elements are other R objects, where each object of the list can be of a different data type, and each object can be of different length and dimension than the other objects. Lists can therefore store all other data types, including other lists.
list("text", "more", 2, c(1,2,3,2)) ## [[1]] ## [1] "text" ## ## [[2]] ## [1] "more" ## ## [[3]] ## [1] 2 ## ## [[4]] ## [1] 1 2 3 2 - data.frame
- For most industrial and data scientists, data frames are the most widely useful type of variable. A data.frame is the list analog to the matrix: it is an
list where all columns must be vectors of the same number of rows (determined with NROW()). However, unlike matrices, different columns can contain different types of data and each row and column must have a name. If not named explicitly, R names rows by their row number and columns according to the data assigned assigned to the column. Data frames are typically used to store the sort of data that industrial engineers and scientists most often work with, and is the closest analog in R to an Excel spreadsheet. Usually data frames are made up of one or more columns of factors and one or more columns of numeric data.
data.frame(rnorm(5), rnorm(5), rnorm(5)) ## rnorm.5. rnorm.5..1 rnorm.5..2 ## 1 0.2939566 1.28985202 -0.01669957 ## 2 0.3672161 -0.01663912 -1.02064116 ## 3 1.0871615 1.13855476 0.78573775 ## 4 -0.8501263 -0.17928722 1.03848796 ## 5 -1.6409403 -0.34025455 -0.62113545
factor(c("a", "b", "c", "a"), levels=c("a","b","c","d"))
## [1] a b c a
## Levels: a b c d
More generally, in R all variables are objects, and R distinguishes between objects by their internal storage type and by their class declaration, which are accessible via the typeof() and class() functions. Functions in R are also objects, and the users can define new objects to control the output from functions like summary() and print(). For more on objects, types and classes, see section 2 of the R Language Definition.
Table 2 summarizes the internal storage and R classes of the main data and variable types.
References
- Stevens, S. S. “On the Theory of Scales of Measurement.” Science. 103.2684 (1946): 677-680. Print.
- R Core Team (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.




You must be logged in to post a comment.